

O conceito de observabilidade vem ganhando espaço no mercado, por ajudar equipes de desenvolvimento, infraestrutura e DevOps a lidar com sistemas distribuídos cada vez mais dinâmicos e complexos, mas por ser ainda novo no mercado pode causar certa confusão sobre suas diferenças entre ele e a monitoração.
Descubra agora todos os detalhes acerca da Observabilidade e como ele pode ajudar sua empresa. Acompanhe!
Conceito de Observabilidade
A observabilidade ajuda os desenvolvedores a entender arquiteturas de várias camadas: o que está lento, o que está quebrado e o que precisa ser feito para melhorar o desempenho. Ao tornar os sistemas observáveis, qualquer pessoa da equipe de tecnologia pode navegar facilmente do efeito à causa em um sistema de produção. O caminho do efeito à causa geralmente requer muitas etapas, incluindo qualquer número de intermediários inocentes. A observabilidade é um meio de seguir cada uma dessas etapas.
Nas palavras de Shaun McCormick, engenheiro sênior da BigCommerce, “observabilidade não é apenas saber que um problema está acontecendo, mas saber por que está acontecendo. E saber como posso entrar e consertar isso.”
Mais formalmente, a observabilidade é definida como a capacidade de medir o estado interno de um sistema apenas por suas saídas. Para sistemas distribuídos, como microsserviços, serverless, service mesh, etc., essas saídas são dados de telemetria: logs, métricas e traces.
Dados de telemetria: logs, métricas e rastreamentos
Existem três tipos principais de dados de telemetria através dos quais os sistemas são observáveis.
Logs
Linhas de texto estruturadas ou não estruturadas que são emitidas por um aplicativo em resposta a algum evento no código. Logs são registros distintos de “o que aconteceu” com algum atributo de sistema específico em um momento específico. Eles são tipicamente fáceis de gerar, difíceis de extrair significado e caros para armazenar.
Exemplo de log estruturado:

Exemplo de log não estruturado:

Métricas
Uma métrica é um valor que expressa alguns dados sobre um sistema. Essas métricas geralmente são representadas como contagens ou medidas e geralmente são agregadas ou calculadas ao longo de um período de tempo. Uma métrica pode informar quanta memória está sendo usada por um processo do total ou o número de solicitações por segundo que estão sendo tratadas por um serviço.
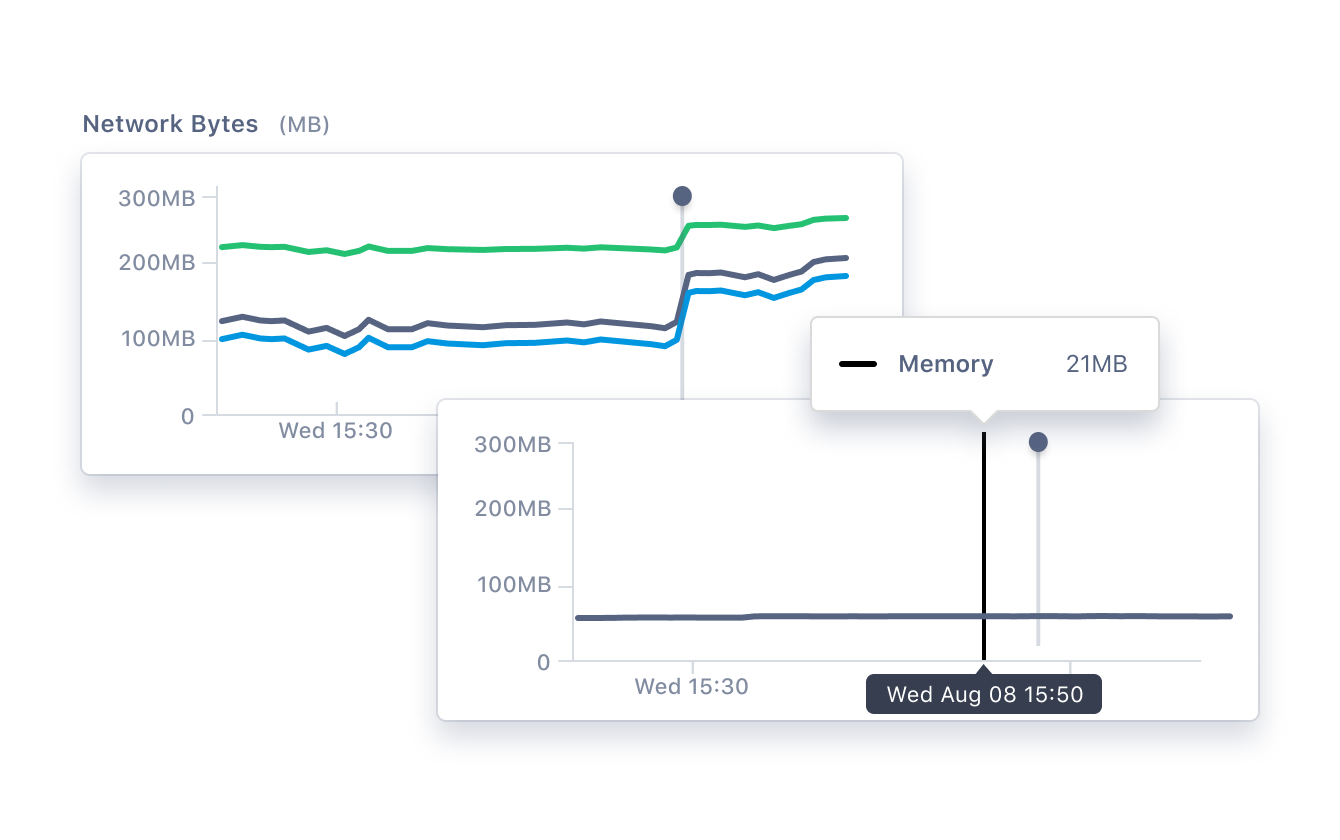
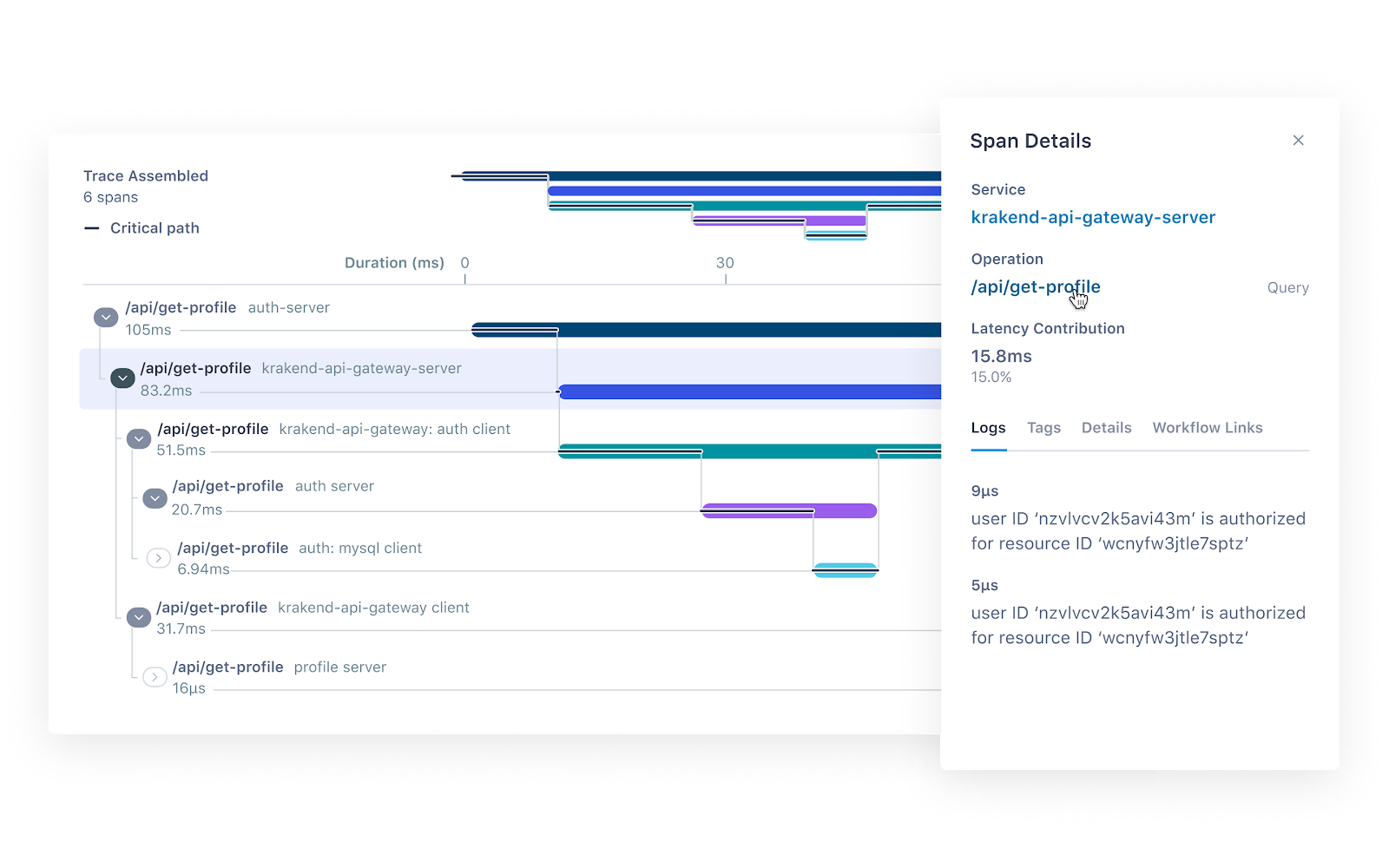
Traces
Um único trace mostra a atividade de uma transação ou solicitação individual conforme ela flui por um aplicativo. Os traces (ou rastreamentos) são uma parte crítica da observabilidade, pois fornecem contexto para outras telemetrias. Por exemplo, os traces podem ajudar a definir quais métricas seriam mais valiosas em uma determinada situação ou quais logs são relevantes para um determinado problema.
Quais perguntas a Observabilidade pode responder?
Separamos uma lista com algumas das principais perguntas que a observabilidade pode te ajudar a responder. Esta é, sem dúvida, uma lista incompleta, como a aplicação da observabilidade é tão ampla, apenas uma amostra de questões que podem ser abordadas por uma solução de observabilidade eficaz:
- Por que x está quebrado?
- De quais serviços o meu serviço depende — de quais serviços dependem meu serviço?
- O que deu errado durante este lançamento?
- Por que o desempenho se degradou no último trimestre?
- Por que meu pager simplesmente disparou?
- O que mudou? Por que?
- Quais registros devemos olhar agora?
- Devemos reverter este cenário?
- Esse problema está afetando alguns usuários do Android ou todos eles?
- Como é o desempenho do sistema para nossos clientes mais importantes?
- Qual SLO devemos definir?
- Estamos fora do SLO?
- Qual era a aparência do meu serviço no momento x?
- Qual era a relação entre meu serviço e x no momento y?
- Qual era a relação de atribuição em todo o sistema antes da implantação? Como é agora?
- O que provavelmente está contribuindo para a latência agora? O que é mais provável que não?
- Essas otimizações de desempenho estão no caminho crítico?
Observabilidade versus APM
Os fornecedores convencionais de monitoramento de desempenho de aplicativos (APM) dependem muito de sampling. Isso significa que, quando você precisa depurar um problema, obtém apenas 1% ou mais dos dados. Claro, o resultado é que há apenas uma chance fracionária de você chegar à causa raiz na primeira tentativa.
Depois que você finalmente encontrou a causa raiz, caso isso exista, há um atraso até que você possa testar novamente. Isso vai arrastar seus esforços de MTTR drasticamente.
Além disso, essas ferramentas usam uma abordagem baseada em agente, que requer CPU. À medida que você entra no mundo dos serviços, contêineres ou até mesmo vários monólitos, isso exigirá recursos adicionais que você precisará considerar.
Por fim, após “x” meses, seus dados se transformarão em resumos de agregação de dados, o que significa que você não terá mais dados de fidelidade total se precisar auditar suas implantações ou tentar encontrar eficiências em seu código.
Pilares da Observabilidade
Historicamente, os três tipos de telemetria são chamados de “três pilares” da observabilidade: tipos de dados separados geralmente com seus próprios painéis.
A crescente escala e complexidade do software levou a mudanças nesse modelo, no entanto, os profissionais não apenas identificaram as inter-relações entre esses tipos de dados de telemetria, mas também os fluxos de trabalho coordenados que os envolvem.
Por exemplo, painéis de métricas de séries temporais podem ser usados para identificar um subconjunto de rastreamentos que apontam para problemas ou bugs subjacentes — e as mensagens de log associadas a esses rastreamentos podem identificar a causa raiz do problema. Em seguida, novas métricas podem ser configuradas para identificar de forma mais proativa problemas semelhantes antes do próximo incidente.
Além disso, quando visualizados de forma agregada, os rastreamentos podem revelar insights imediatos sobre o que está causando o maior impacto no desempenho ou na experiência do cliente e mostrar apenas as métricas e os logs relevantes para um problema.
Digamos que haja uma regressão repentina no desempenho de um serviço de back-end específico, no fundo de sua pilha. Acontece que o problema subjacente era que um de seus muitos clientes mudou seu padrão de tráfego e começou a enviar solicitações significativamente mais complexas. Isso seria óbvio em segundos depois de analisar as estatísticas de rastreamento agregadas, embora levasse dias apenas analisando logs, métricas ou até rastreamentos individuais por conta própria.

Resumindo: observabilidade não é simplesmente telemetria – é como se essa telemetria fosse utilizada para resolver problemas e, em última análise, criar uma experiência melhor para os clientes.
Benefícios da observabilidade
Os sistemas observáveis são mais fáceis de entender, controlar e consertar. À medida que os sistemas mudam – seja de propósito porque você está implantando um novo software, uma nova configuração ou aumentando ou diminuindo a escala, ou talvez por causa de alguma outra ação desconhecida – a observabilidade permite que os desenvolvedores entendam quando o sistema começa a não estar no estado pretendido.
As ferramentas modernas de observabilidade podem identificar automaticamente vários problemas e suas causas, como falhas causadas por alterações de rotina, regressões que afetam apenas clientes específicos e erros de downstream em serviços e SaaS (Software as a Service) de terceiros.
Benefícios da observabilidade por função
Desenvolvedores
A observabilidade reduz a quantidade de estresse ao implantar o código ou fazer alterações no sistema. Ao destacar “o que mudou” após qualquer implantação ou alerta sobre valores discrepantes, os problemas que afetam o cliente podem ser encontrados rapidamente e revertidos antes que os SLOs sejam interrompidos.
Com uma compreensão em tempo real das dependências do sistema completo, os desenvolvedores gastam muito menos tempo em reuniões. Não há mais motivo para esperar uma ligação para ver quem é o proprietário de um serviço específico ou como era o sistema horas, dias ou meses antes da implantação mais recente.
Ao revelar o caminho crítico das solicitações de ponta a ponta e apresentar apenas os dados relevantes para resolver um problema, a observabilidade permite melhores fluxos de trabalho para depuração, otimização de desempenho e combate a incêndios. Descartando sinais que provavelmente não contribuíram para a causa raiz, os desenvolvedores podem formar e investigar hipóteses mais eficazes.

Equipes
Para equipes de todos os tamanhos, a observabilidade oferece uma visão compartilhada do sistema. Isso inclui sua integridade, sua arquitetura, seu desempenho ao longo do tempo e como as solicitações passam de front-end/aplicativos da Web para serviços de back-end e de terceiros.
A observabilidade fornece contexto entre funções e organizações, pois permite que desenvolvedores, operadores, gerentes, PMs, contratados e quaisquer outros membros da equipe trabalhem com as mesmas visualizações e insights sobre serviços, clientes específicos, consultas SQL etc.
Como as ferramentas de observabilidade permitem a captura automatizada de qualquer momento no tempo, elas servem como um registro histórico da arquitetura do sistema, dependências e integridade do serviço — tendo histórico de o que foi e o que mudou ao longo do tempo.
Negócios
Em última análise, ao tornar um sistema observável, as organizações podem liberar mais código, com mais rapidez e segurança.
O que geralmente determina se sua empresa é bem-sucedida ou não é a capacidade de mudar e enviar novos recursos. Mas essa mudança é diretamente oposta à estabilidade de seus sistemas. E então há essa tensão básica: você precisa mudar para poder expandir seus negócios. Mas sempre que a mudança é introduzida, o risco é introduzido e pode criar resultados negativos de um senso de negócios.
A observabilidade resolve essa tensão básica. As empresas podem fazer mudanças com níveis mais altos de confiança e descobrir se estão ou não tendo o efeito pretendido e limitar o impacto negativo da mudança.
O resultado são lançamentos mais confiantes em uma velocidade mais alta. Você pode implantar com mais frequência e com mais confiança, pois possui ferramentas que o ajudarão a entender o que está errado, isolar quaisquer problemas e fazer melhorias imediatas.
Em última análise, ele permite que você mantenha os clientes satisfeitos com menos tempo de inatividade, novos recursos e sistemas mais rápidos.

Como você pode notar a observabilidade traz muitas vantagens para sua empresa, e se caso você tenha interesse em saber mais sobre essa tecnologia, acompanhe outros artigos do nosso blog sobre esse tema. E se for do seu interesse implementa-la em sua empresa, saiba que temos profissionais qualificados aqui na OpServices para te ajudar nessa missão. Entre em contato com nossos especialistas.
Este artigo é uma tradução livre do artigo What is Observability.









